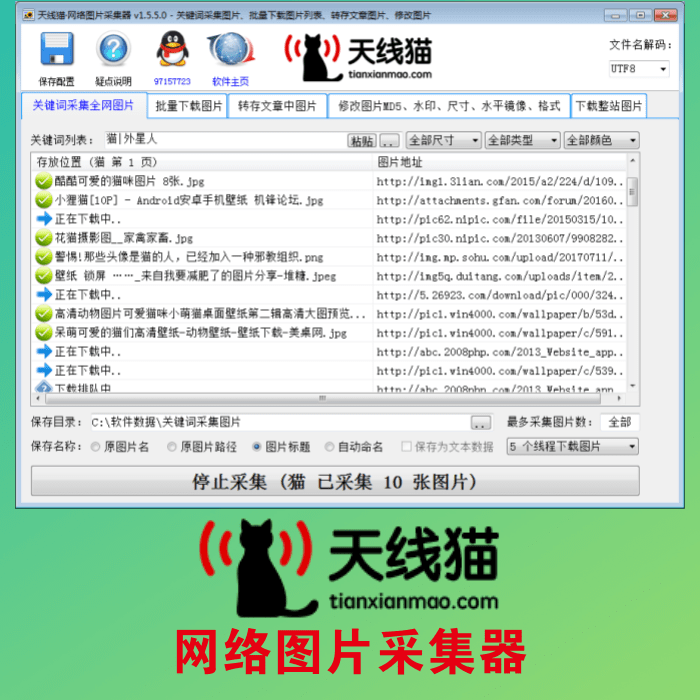
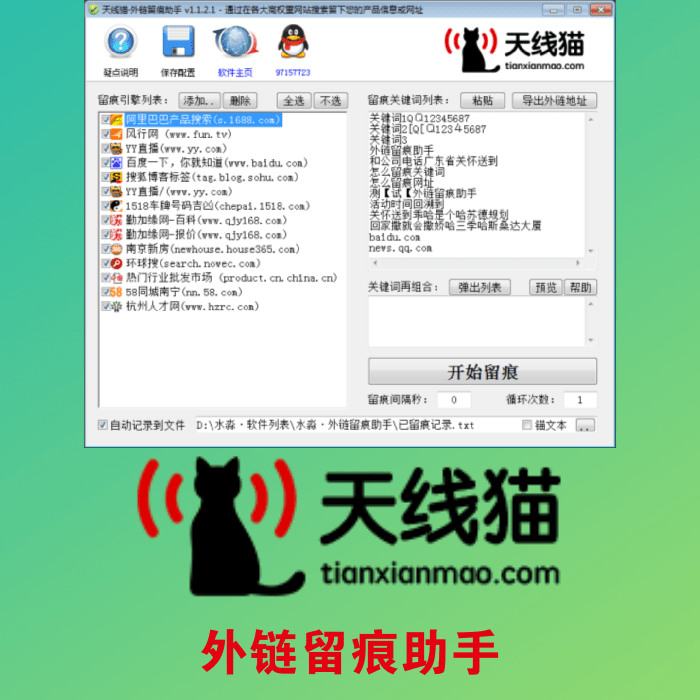
网友反映,从早上八点开始,华为云登录、治理后台便开始无法访问,并出现了“服务器暂时过载或处于维护中,请稍后重试。”、“建立数据库连接时出错”等提示。
此现象说明华为云出现了宕机事故。
有网友表示,此次故障对企业影响很大,公司电话已经被打爆,部门主管和运维在疯狂敲键盘。还有网友称,公司游戏全部宕机。还有网友发帖,纪录这是“历史性的一刻”,究竟华为云是第一次出现宕机事故。
在事故发生后的3个小时,华为云才发布公告,称4月10日上午检测到部分主机异常,目前故障基本修复,部分客户的业务正在配合恢复中。
假如算上华为云此次宕机事故,全球知名的云计算企业已经全部遭受过宕机事故,应该说宕机已经成为了云计算企业的标配,我们逐一盘点。

AWS是目前云计算全球市场占有率很高的企业,在2021年出现过4次宕机。
2021年6月24日,亚马逊旗下云业务部门AmazonWebServices(AWS)刚刚证实,由于一家外部服务提供商出现问题,影响了部分客户网络和多个AWS区域(AWSRegion)之间的互联网连接。
今日稍早些时候,追踪网站故障的Downdetector.com网站称,从美国东部时间早上8点32分(北京时间晚上8点32分),亚马逊AWS云服务出现宕机。
亚马逊同时强调,由其他外部服务提供商提供的服务,与所在AWS区域内的连接不受影响。

本月初,亚马逊AWS在中国的光缆曾因道路施工被挖断,导致不少服务中断,包括VIPKID、流利说和三星应用商店等多个服务的用户都均受到不同程度的影响。
仅仅过了4个月,AWS再次出现宕机事故。
2021年10月22日,亚马逊遭DDoS攻击,部分AmazonWebServices(AWS)宕机,导致客户的网站濒临崩溃。
由于攻击导致AWS服务持续中断,不幸的网民遭遇了间歇性访问互联网AWS站点和相关服务失败的痛苦经历。
对此,亚马逊的技术支持代理第一个现身说法——这不是天灾,是人祸!
他称,由于AWSDNS服务器受到分布式拒绝服务(DDoS)攻击的阻碍,攻击者试图用垃圾网络流量沉没系统,导致服务无法访问。
有客户反映,攻击疑似从美国时间9点开始,这之后大约10个小时亚马逊的AWS服务都处于宕机状态。
在这种情况下,亚马逊的DNS系统被大量数据包所阻塞,其中一些合法的域名请求被释放并用于缓解流量阻塞。
2021年7月16日,如同国内电商们的双十一一样,亚马逊在美国也创造了自己的购物节日AmazonPrimeDay(亚马逊会员日)。
但是,在第四届亚马逊会员日当日的开幕仪式后几分钟,大规模的故障使得7月16日的销售陷入了瘫痪。
AWS的发言人表示,这些问题与AWS无关。
但是对于全球很大的电商网站来说,失败就是失败了,这个网站是在据说是世界上很领先的云上托管的。许多消费者乘兴而来败兴而归,得到的只有一个宕机通知。
但尽管如此,但该客户日的销售业绩仍然破了纪录。
2021年5月31日,因北弗吉尼亚地区的数据中心中的硬件问题,该云巨头又一次出现了连接问题。
其影响时间大约为30分钟,在此期间用户报告说因硬件错误,所有的数据不能得以被全部再存储。
该宕机是“由数据中心和一些网络设备中的一些物理服务器上的电力事件引起的”,AWS在事后报告中写到。
AWS的核心EC2服务,Workspaces虚拟桌面服务以及Redshift数据仓库服务都受到了影响。
2021年3月2日,AWS的宕机广泛影响了大量的Alexa语音助手的用户,并波及到了很多热门在线服务商,如Atlassian、Slack和Twilio。
稍后,亚马逊表示他们位于弗吉尼亚数据中心在早上碰到了强烈东北风暴的冲击,而使得网络连接出现了问题。
这场风暴切断了AWS北弗吉尼亚地区与两个东海岸运营商Equinix和CoreSite连接。
2021年2月28日,AWS,这次宕机事件极为轰动,相信大家对此记忆尤深。当时是一位AWS工程师试图调试亚马逊的弗吉尼亚数据中心S3存储系统,但输入了一个错误指令,导致许多互联网——包括诸如Slack,Quora和Trello等众多企业平台宕机4个小时。
亚马逊在事件后分析表示,该员工当时当时打算将一小部分用于计费过程的托管子系统服务器删除。然而,错误命令导致了更多的服务器脱机,包括为数据存储功能提供特定请求所需的一个子系统和另一个分配新存储空间的子系统。
亚马逊坐拥约三分之一的全球云市场,因此这次宕机事件重新引发了关于公有云的风险论。
接下来是云计算全球市场占有率排名第二的微软Azure宕机事故,从2021年到2021年,共出现过5次宕机事故。
2021年8月,微软云服务Azure的主要组件发生全球大范围宕机。
2021年11月,美国东部时间下午8点20分(北京时间9点20分)再次出现宕机事件,影响多个国家和地区。
微软支持页面并未就导致服务宕机的原因进行说明,只是表明15家数据中心的“储存”处于停电状态,不能正常工作。
随后微软官方发布了一则快讯,称:
自世界标准时间2021年11月19日00点52分,包括储存、网站和VisualStudioOnline的AzureServices出现了连接问题。我们将会在60分钟后更新状态说明。
此外本次Azure云服务宕机对包括OneDrive和XboxLive在内的多项微软服务也造成了影响,不仅造成了经济上的损失,更是对Azure的品牌声誉产生影响。
2021年3月7日,微软Azure公有云出现宕机事故,微软Azure公有云出现超过8小时的存储可用性问题,主要影响到美国东部的客户。有些用户无法配置新的存储空间或访问本地现有资源。之后,一个微软工程团队确认原因为断电导致的存储集群不可用。
除此之外,微软还在Azure状态页上列出了一个软件错误,该错误影响跨多个服务的存储配置超过一个小时。
2021年3月21日,微软Azure在同一个月内出现第二次宕机,微软的Outlook、Hotmail、OneDrive、Skype和XboxLive都出现了网络故障,全球用户都无法登陆。
英国海岸和美国海岸城市的Outlook邮箱系统的用户受到的影响尤其严重,同样悲惨的还有西欧与美国海岸线的美国OneDrive用户,西欧和巴西的Skype用户,及Xbox的英国、美国、西欧用户。Azure用户的一天也不好过,一大批工程师无法登陆系统。
2021年6月19日,MicrosoftSkype出现宕机,主要分布在欧洲的微软Skype用户由于遭受明显的分布式阻断服务攻击,接连出现宕机问题。
6月19日,Skype用户开始抱怨多个小时的宕机问题。这次宕机持续到次日,用户在通信平台上无法连接,交流信息受阻。
虽然微软没有立即确认DDoS攻击的报道,但一个名为CyberTeam的黑客组织在推特上承认该事件是他们所为。
2021年4月6日,大量欧洲、亚州和美国的微软客户的电子邮件账户出现了问题。

其中英国受影响很为巨大,由于Office365的宕机,许多企业无法发送邮件与登录Skype。
一些用户报告说他们只能使用单点登录来登录那些办公生产力套件。
有些讽刺的是,这次事件距离微软发布全新Office365安全保护功能后仅一天。
2021年6月17日,微软Azure,由热浪而引发的存储和网络中断使得欧洲的许多微软云客户在17,18日两日间与他们的数据分开了超过5小时的时间。
微软表示,在爱尔兰尤其炎热的夏季里,一个在爱尔兰的数据中心恒温系统出现了问题。
2021年9月5日,微软发现自己在9月的第一周就在两个方面出现了问题。
第一个是,9月5日全世界用户都碰到了部分时间时无法访问365Outlook或SkypeforBusiness的情况。用户报告说,当他们尝试登录微软时,他们会受到一条错误消息,说“受到限制”。
微软将这次终端归咎于Azure后端身份验证系统的更新问题。
与此同时,在4日到5日两天里,微软在圣安东尼奥的数据中心遭遇了雷击,这导致了美国中南部区域中Azure和Office365服务的中断。
2021年11月18日,据微软披露,11月18日,一些用户无法登录Azure和Office365服务。
这次宕机影响了许多需要身份验证而登录云服务的用户,并横跨整个欧洲、亚太和美洲地区,从当地时间周日晚上11:39起开始影响Azure和Offic365服务。
2021年5月3日,微软的Azure在全球范围内出现了大面积宕机,整个过程持续了将近2个小时,直到5点30分才完全恢复。受Azure宕机影响,包括Microsoft365,Dynamics和DevOps在内的微软主要服务均出现使用问题。
现在微软官方发布声明,表示本次出现全球性宕机问题是由于“名称服务器授权”问题所导致的。微软解释道:“工程师确认是由于影响DNS解析的名称服务器授权调整影响底层root,并影响下游对计算,存储,应用服务,AAD和SQL数据库服务。在将旧DNS系统迁移到AzureDNS期间,Microsoft服务的某些域未正确更新。在此事件期间,没有客户DNS记录受到影响,并且整个事件期间AzureDNS的可用性保持在100%。该问题仅影响Microsoft服务的记录。”
阿里云云计算在全球市场排名第三,我们看看近年来他们的宕机事故。
2021年3月3日凌晨,有不少网友微博上反馈称阿里云疑似出现了宕机故障,华北很多互联网公司都受到波及,APP和网站都瘫痪了。凌晨2点37分,阿里云发布通报称,华北2地域可用区C部分ECS服务器(云服务器)等实例出现IOHANG(IO不响应),经紧急排查处理后已全部恢复。
阿里云方面表示,目前已经全面排查其他地域及可用区,未发现此类情况。针对本次故障,将根据SLA协议(服务合同),尽快处理赔偿事宜。此外,阿里还表示,“针对本次故障,我们将根据SLA协议,尽快处理赔偿事宜。”
SLA协议”即,服务等级协议(ServiceLevelAgreement,简称“SLA”)。根据阿里云官网资料显示,对于单ECS实例,如服务可用性低于99.95%,用户可获得月度服务费10%、25%、100%不等的赔偿。
云服务发生故障的赔偿基本以“送时间”为主,比如此前,阿里云就执行过“百倍时间赔偿”。
有数据显示,中国目前有40%的网站部署在阿里云上。作为国内很大的公有云厂商,阿里云占据中国45%的云计算市场份额。说得更简单,阿里云一出现问题,简直波及一大批企业。
作为全球第三大、亚洲、国内很大的云服务商,这并不是阿里云第一次宕机。
2021年6月,阿里云出现大规模访问异常,图片服务等产品无法正常使用,官网账号也无法登陆。官方公布,该故障是因为运维上的一个操作失误。事后,阿里云表示,将敬畏每一行代码,敬畏每一份托付。
2021年10月,阿里云华东1地域可用区B部分也曾发生过ECS服务器IOHANG的事故。
2020年9月,阿里云云盾的安骑士产品升级触发bug导致了用户ECS里的部分正常文件被误隔离。原因是,程序员写错了一行代码。也是在当年,阿里云启动了“百倍时间赔偿计划”。
另有媒体统计,2021年、2021年、2021年阿里云都曾出现不同程度的故障。
根据IDC数据显示,IBM云全球排名第四,看看他们的宕机事故。
2021年7月4日,IBM云存储在UTC时间0525发生了到抖动,一位心怀不满的客户说,这使得他公司的大部分iSCSI设备“无法使用”。
“IBM云工程团队继续共同努力,找出目前在AMS01,AMS03,FRA02,FRA04,MIL01中出现的存储问题的原因和解决方案,”这是IBM云今天上午10:09发布给客户的更新说明。
2021年1月26日,IBM云的信用度受到影响,客户用于访问其Bluemix云基础架构(以前称为SoftLayer)的一个治理网站服务中断了数小时。
虽然底层基础架构没有真的出现故障,但用户发现他们无法治理自身的应用程序,添加或删除支持工作负载的云资源。
IBM表示该问题是由于一次接口升级造成,只是间歇性的。
2021年5月22日,在IBM云上的热门瑜伽网站Lululemon出现服务中断问题,其首席执行官将主要责任归咎于IBM的托管云服务。
Lululemon首席执行官,LaurentPotdevin在接受CNBC(美国全国广播公司财经频道)采访时直接指责在IBM云环境下电子商务销售额遭受了损失。并表示他的团队由于这个问题连续工作了36个小时,并已经向IBMCEO,GinniRometty表达了不满。
文章地址:https://www.tianxianmao.com/article/online/12113.html